| System Management Services (SMS) 1.2 Administrator Guide |
|
| System Management Services (SMS) 1.2 Administrator Guide |
|
| C H A P T E R 8 |
SC Failover |
SC failover maximizes Sun Fire 15K system uptime by adding high availability features to its administrative operations. A Sun Fire 15K system contains two SCs. Failover provides software support to a high-availability two SC system configuration.
The main SC provides all resources for the entire Sun Fire 15K system. If hardware or software failures occur on the main SC or on any hardware control path (for example, console bus interface or Ethernet interface) from the main SC to other system devices, then SC failover software automatically triggers a failover to the spare SC. The spare SC then assumes the role of the main and takes over all the main SC responsibilities. In a high-availability two SCs system configuration, SMS data, configuration, and log files are replicated on the spare SC. Active domains are not affected by this switch.
In the current high-availability SC configuration, one SC acts as a "hot spare" for the other.
Failover eliminates the single point of failure in the management of the Sun Fire 15K system. fomd identifies and handles as many multiple points failure as possible. Some failover scenarios are discussed in Failure and Recovery .
At anytime during SC failover, the failover process does not adversely affect any configured or running domains except for temporary loss of services from the SC.
In a high-availability SC system:
If a fault (software or hardware) is detected on the main SC, fomd automatically fails over to the spare SC.
If the spare SC detects that the main SC has stopped communicating with it, it initiates a takeover and assumes the role of main.
The failover management daemon ( fomd (1M)) is the core of the SC failover mechanism. It is installed on both the main and spare SC.
Determines an SC's role; main or spare.
Requests the general health status of the remote SC hardware and software in the form of a periodic health status message request sent over the SMS management network (MAN) that exists between the two SCs.
Checks and/or handles recoverable and unrecoverable hardware and software faults.
Makes every attempt to eliminate the possibility of split-brain condition between the two SCs. [A condition is considered split-brain when both the SCs think they are the main SC.]
Provides a recovery time from a main SC failure of between five and eight minutes. The recovery time includes the time for fomd to detect the failure, reach an agreement on the failure, and assume the main SC responsibilities on the spare SC.
Logs an occurrence of an SC failover in the platform message log.
Services that would be interrupted during a SC failover include:
All network connections
Any SC-to-domain and domain-to-SC IOSRAM/Mailbox communication
Any process running on the main SC.
You do not need to know the hostname of the main SC in order to establish connections to it. As part of configuring SMS (refer to the
smsconfig
(1M) man page), a logical hostname was created which will always be active on the main SC. Refer to the
Sun Fire 15K System Site Planning Guide
and the
System Management Services (SMS) 1.2 Installation Guide and Release Notes
for information on the creation of the logical hostnames in your network database.
15K System Site Planning Guide
and the
System Management Services (SMS) 1.2 Installation Guide and Release Notes
for information on the creation of the logical hostnames in your network database.
Operations interrupted by an SC failover can be recovered after the failover completes. Reissuance of the interrupted operation causes the operation to resume and continue to completion.
All automated functions provided by fomd resume without operator intervention after SC failover. Any recovery actions interrupted before completion by the SC failover will restart.
There are three types of failovers:
Main initiated
A main initiated failover is where the fomd running on the main SC yields control to the spare SC in response to either an unrecoverable local hardware/software failure or an operator request.
Spare initiated (takeover)
A spare initiated failover (takeover) is where the fomd running on the spare determines that the main SC is no longer functioning properly.
Indirect triggered takeover
If the I2 network path between the SCs is down and there is a fault on the main, then the main switches itself to the role of spare and upon detecting this, the spare SC assumes the role of main.
In the last two scenarios, the spare fomd eliminates the possibility of a "split-brain" condition by resetting the main SC.
When a failover occurs, either software controlled or user forced, fomd deactivates the failover mechanism. This eliminates the possibility of repeatedly failing over back and forth between the two SCs.
One of the purposes of the fomd is propagation of data from the main SC to the spare SC through the interconnects that exist between the two SCs. This data includes configuration, data, and log files.
Propagates all native SMS files from the main to the spare SC at startup. These include all the domain data directories, the pcd configuration files, the /etc/opt/SUNWSMS/config directory, the /var/opt/SUNWSMS/adm platform and domain files, and the .logger files. Any user-created application files are not propagated unless specified in the cmdsync scripts.
Only propagates files modified since the last propagation cycle.
In the event of a failover, propagates all modified SMS files before the spare SC assumes its role as main.
The I2 network must be operative for the transfer of data to occur.
|
Note - Any changes made to the network configuration on one SC using smsconfig -m must be made to the other SC as well. Network configuration is not automatically propagated. |
Should both interconnections between the two SCs fail, failover can still occur provided main and spare SC accesses to the high-availability srams (HASram) remain intact. Due to the failure of both interconnections, propagation of SMS data can no longer occur, creating the potential of stale data on the spare SC. In the event of a failover, fomd on the new main keeps the current state of the data, logs the state and provides other SMS daemons/clients information of the current state of the data.
When either of the interconnects between the two SCs is healthy again, data is pulled over depending on the timestamp of each SMS files. If the timestamp of the file is earlier than the one on the now spare SC, it gets transferred over. If the timestamp of the file is later than the one on the spare SC, no action is taken.
Failover cannot occur when both of the following conditions are met:
This is considered a quadruple fault, and failover will be disabled until at least one of the links is restored.
For the failover software to function, both SCs must be present in the system. The determination of main and spare roles are based in part on the SC number. This slot number does not prevent a given SC from assuming either role, it is only meant to control how it goes about doing so.
If SMS is started on one SC first, it will become main. If SMS starts up on both SCs at essentially the same time, whichever SC first determines that the other SC either is not main or is not running SMS will become main.
There is one case during start-up where, if SC0 is in the middle of the start-up process, and it queries SC1 for its role and the SC1 role cannot be confirmed, SC0 will try to become main. SC0 will reset SC1 during this process. This is done to prevent both SCs from assuming the main role; a condition known as "split brain." The reset will occur even if the failover mechanism is deactivated.
Upon startup, the fomd running on the main SC begins periodically testing the hardware and network interfaces. Initially the failover mechanism is disabled (internally) until at least one status response has been received from the remote (spare) SC indicating that it is healthy.
If a local fault is detected by the main fomd during initial startup, failover occurs when all of the following conditions are met:
The I2 network was not the source of the fault.
The remote SC is healthy (as indicated by the health status response).
The failover mechanism has not been deactivated.
Upon startup, fomd runs on the spare SC and begins periodically testing the software, hardware, and network interfaces.
If a local fault is detected by the fomd running on the spare SC during initial startup, it informs the main fomd of its debilitated state.
setfailover modifies the state of the SC failover mechanism. The default state is on. You can set failover to:
For more information and examples refer to the setfailover man page.
showfailover allows you to monitor the state and display the current status of the SC Failover mechanism. The -v option displays the current status of all monitored components.
The -r option displays the SC role: main, spare or unknown. For example:
If you do not specify an option, then only the state information is displayed:
The failover mechanisms may be in one of three states: ACTIVE, DISABLED, and FAILED.
In addition showfailover displays the state of each of the network interface links monitored by the failover processes. The display format is as follows:
showfailover returns a failure string describing the failure condition. Each failure string has a code associated with it. The following table defines the codes, and associated failure strings.
For examples and more information, refer to the showfailover man page.
If an SC failover occurs during the execution of a command, you can restart the same command on the new main SC.
All commands and actions are recorded to do the following:
Mark the start of a command or action.
Remove or indicate the completion of a command or action.
Keep any state transition and/or pertinent data which SMS can use to resume the command.
Command sync support for dsmd (1M) to automatically resume ASR reboots of any or all affected domain(s) after a failover.
Command sync support for all SMS DR related daemons and CLIs to recover the last DR operation after a failover.
The four CLIs in SMS that require command sync support are addboard , deleteboard , moveboard , and rcfgadm .
The cmdsync commands provide the ability to initialize a script or command with a cmdsync descriptor, update an existing cmdsync descriptor execution point, or cancel a cmdsync descriptor from the spare SC's list of recovery actions. Commands or scripts can also be run in a cmdsync envelope.
In the case of an SC failover to the spare, initialization of a cmdsync descriptor on the spare SC allows the spare SC to restart or resume the target script or command from the last execution point set. These commands only execute on the main SC, and have no effect on the current cmdsync list if executed on the spare.
Commands or scripts invoked with the cmdsync commands when there is no enabled spare SC will result in a no-op operation. That is, command execution will proceed as normal, but a log entry in the platform log will indicate that a cmdsync attempt has failed.
initcmdsync (1M) creates a cmdsync descriptor. The target script or command and its associated parameters are saved as part of the cmdsync data. The exit code of the initcmdsync command provides a cmdsync descriptor that can be used in subsequent cmdsync commands to reference the action. Actual execution of the target command or script is not performed. For more information, refer to the initcmdsync (1M) man page.
savecmdsync (1M) saves a new execution point in a previously defined cmdsync descriptor. This allows a target command or script to restart execution at a location associated with an identifier. The target command or script supports the ability to be restarted at this execution point, otherwise the restart execution is at the beginning of the target command or script. For more information, refer to the savecmdsync (1M) man page.
cancelcmdsync (1M) removes a cmdsync descriptor from the spare restart list. Once this command is run, the target command or script associated with the cmdsync descriptor is not restarted on the spare SC in the event of a failover. Take care to insure that all target commands or scripts contain a initcmdsync command sequence as well as a cancelcmdsync sequence after the normal or abnormal termination flows. For more information, refer to the cancelcmdsync (1M) man page.
runcmdsync (1M) executes the specified target command or script under a cmdsync wrapper. You cannot restart at execution points other than the beginning. The target command or script is executed through the system command after creation of the cmdsync descriptor. Upon termination of the system command, the cmdsync descriptor is removed from the cmdsync list, and the exit code of the system command returned to the user. For more information, refer to the runcmdsync (1M) man page.
showcmdsync (1M) displays the current cmdsync descriptor list. For more information, refer to the showcmdsync (1M) man page.
In a high-availability configuration, fomd manages the failover mechanism on the local and remote SCs. fomd detects the presence of local hardware and software faults and determines the appropriate action to take.
fomd is responsible for detecting faults in the following categories:
FIGURE 8-1 illustrates the failover fault categories.
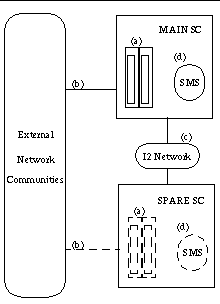
The following table illustrates how faults in the above-mentioned categories affect the failover mechanism. Assume that the failover mechanism is activated.
The following lists events for the main fomd during SC failover in order.
Detects the fault.
Stops generating heartbeats.
Tells the remote failover software to start a takeover timer. The purpose of this timer is to provide an alternate means for the remote (spare) SC to takeover if for any reason the main hangs up and never reaches Number 10.
Starts the SMS software in spare mode.
Removes the logical IP interface.
Enables the console bus caging mechanism.
Triggers propagation of any modified SMS files to the spare SC/HASrams.
Stops file propagation monitoring.
Shuts down main-specific daemons and sets its role to UNKNOWN.
Logs a failover event.
Notifies remote (spare) failover software that it should assume the role of main. If the takeover timer expires before the spare is notified, the remote SC will takeover on its own.
The following lists the order of events for the spare fomd during failover.
Receives message from the main fomd to assume main role, or the takeover timer expires. If the former is true, then the takeover timer is stopped.
Resets the old main SC.
Notifies hwad , frad , and mand to configure itself in the main role.
Assumes the role of main.
Starts generating heartbeat interrupts.
Configures the logical IP interface.
Disables the console bus caging mechanism.
Starts the SMS software in main mode.
Prepare the DARBs to receive interrupts.
Logs a role reversal event, spare to main.
The spare SC is now the main and fomd deactivates the failover mechanism.
In this scenario the spare SC takes main control in reaction to the main SC going away. The most important aspect of this type of failover is the prevention of the split-brain condition. Another assumption is that the failover mechanism is not deactivated. If this is not the case, then no takeover can occur.
The spare fomd does the following:
Notices the main SC is not healthy.
From the spare fomd perspective, this phenomenon can be caused by two conditions; the main SC is truly dead, and/or the I2 network interface is down.
In the former case, a failover is needed (provided that the failover mechanism is activated) while in the latter it is not. To identify which is the case, the spare fomd polls for the presence of heartbeat interrupts from the main SC to determine if the main SC is still up and running. The polling period for this is configurable. As long as there are heartbeat interrupts being received, and/or the failover mechanism is deactivated and/or disabled, no failover occurs. In the case where no interrupts are detected, but the failover mechanism is deactivated, the spare fomd does not attempt to take over unless the operator manually activates the failover mechanism using the CLI command, setfailover . Otherwise, if the spare SC is healthy, the spare fomd proceeds to take over the role of main as listed.
Initiates a takeover by resetting the remote (main) SC.
The following lists the events for the spare fomd , in order, during failover.
Reconfigures itself as main. This includes taking over control of the I2C bus, configuring the logical main SC IP address, and starting up the necessary SMS software daemons.
Starts generating heartbeat interrupts.
Configures the logical IP interface.
Disables console bus caging.
Starts the SMS software in main mode.
Configures the darb interrupts.
Logs a takeover event.
The spare fomd , now the main, deactivates the failover mechanism.
The following lists the events, in order, that occur after an I2 network fault.
The main fomd detects the I2 network is not healthy.
The main fomd stops propagating files and checkpointing data over to the spare SC.
The spare fomd detects the I2 network is not healthy. From the spare fomd perspective, this phenomenon can be caused by two conditions; the main SC is truly dead, and/or the I2 network interface is down. In the former case, the corrective action is to fail over, while in the latter it is not. To identify which is the case, the fomd starts polling for the presence of heartbeat interrupts from the main SC to determine if the main SC is still up and running. If heartbeat interrupts are present, then the fomd keeps the spare as spare.
The spare fomd clears out the checkpoint data on the local disk.
The following lists the events, in order, that occur after a fault on the main SC.
The main fomd detects the fault.
If the last known state of the spare SC was good, then the main fomd stops generating heartbeats. Otherwise failover does not continue.
If the access to the console bus is still available, main failover software finishes propagating any remaining critical files to HASram and flushes out any or all critical state information to HASram.
The main fomd reconfigures the SMS software into spare mode.
The main fomd removes the logical main SC IP address.
The main fomd stops generating heartbeat interrupts.
The following lists the events, in order, that occur during an I2 network fault recovery.
The main fomd detects the I2 network is healthy.
If the spare SC is completely healthy as indicated in the health status response message, the fomd enables failover and, assuming that the failover mechanism has not been deactivated by the operator, does a complete re-sync of the log files and checkpointing data over to the spare SC.
The spare fomd detects the I2 network is healthy.
The spare fomd disables failover and clears out the checkpoint data on the local disk.
The following lists the events, in order, that occur during a reboot and recovery. A reboot and recovery scenario happens in the following two cases.
Assume SSCPOST passed without any problems. If SSCPOST failed and OS cannot be booted, the main is inoperable.
Assume all SSC Solaris drivers attached without any problems. If the SBBC driver fails to attach, see Fault on Main SC (Spare Takes Over Main Role) , if any other drivers fail to attach, see Failover on Main SC (Main Controlled Failover) .
The main fomd is started.
If the fomd determines that the remote SC has already assumed the main role, then see Number 5 in Spare SC Receives a Master Reset or Its UltraSPARC Receives a Reset . Otherwise proceed to Number 5 in this list.
The fomd configures the logical main IP address and starts up the rest of the SMS software.
SMS daemons start in recovery mode if necessary.
Main fomd starts generating heartbeat interrupts.
At this point, the main SC is fully recovered.
Assume SSCPOST passed without any problems. If SSCPOST failed and OS cannot be booted, the spare is inoperable.
Assume all SSC Solaris drivers attached without any problems. If the SBBC driver fails to attach, or any other drivers fail to attach, the spare SC is deemed inoperable.
The fomd is started.
The fomd determines that the SC is the preferred spare and assumes spare role.
The fomd starts checking for the presence of heartbeat interrupts from the remote (initially presumed to be main) SC. If after a configurable amount of time no heartbeat interrupts are detected, then the failover mechanism state is checked. If enabled and activated, fomd initiates a take over. Now refer to Number 5 of Main SC Receives a Master Reset or Its UltraSPARC Receives a Reset . Otherwise, fomd continues monitoring for the presence of heartbeat interrupts and the state of the failover mechanism.
The fomd starts periodically checking the hardware/software and network interfaces.
The fomd configures the local main SC IP address.
At this point, the spare SC is fully recovered.
The following lists the events that occur during a client failover recovery. A recovery scenario happens in the following two cases.
Clients with any operations in progress are manually recovered by checkpointing data unless they are non-recurring.
Since the I2 network is down, all checkpointing data are removed. Clients cannot perform any recovery.
Same as Fault on Main SC-- Recovering From the Spare SC
All failover specific network traffic (such as health status request/response messages and file propagation packets) are sent only over the interconnect network that exists between the two SCs.
| System Management Services (SMS) 1.2 Administrator Guide | 816-3267-10 |
|
Copyright © 2002, Sun Microsystems, Inc. All rights reserved.