

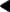
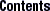

How Servers Propagate Changes
An NIS+ master server implements updates to its objects immediately; however, it tries to "batch" several updates together before it propagates them to its replicas. When a master server receives an update to an object, whether a directory, group, link, or table, it waits about two minutes for any other updates that may arrive. Once it is finished waiting, it stores the updates in two locations: on disk and in a transaction log (it has already stored the updates in memory).
The transaction log is used by a master server to store changes to the namespace until they can be propagated to replicas. A transaction log has two primary components: updates and time stamps.

An update is an actual copy of a changed object. For instance, if a directory has been changed, the update is a complete copy of the directory object. If a table entry has been changed, the update is a copy of the actual table entry. The time stamp indicates the time at which an update was made by the master server.
After recording the change in the transaction log, the master sends a message to its replicas, telling them that it has updates to send them. Each replica replies with the time stamp of the last update it received from the master. The master then sends each replica the updates it has recorded in the log since the replica's time stamp:
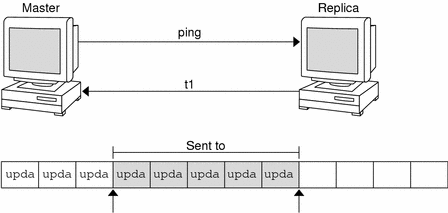
When the master server updates all its replicas, it clears the transaction log. In some cases, such as when a new replica is added to a domain, the master receives a time stamp from a replica that is before its earliest time stamp still recorded in the transaction log. If that happens, the master server performs a full resynchronization, or resync. A resync downloads all the objects and information stored in the master down to the replica. During a resync, both the master and replica are busy. The replica cannot answer requests for information; the master can answer read requests but cannot accept update requests. Both respond to requests with a Server Busy - Try Again or similar message.
NIS+ Clients and Principals
NIS+ principals are the entities (clients) that submit requests for NIS+ services.
Principal
An NIS+ principal may be someone who is logged in to a client machine as a regular user or someone who is logged in as superuser (root). In the first instance, the request actually comes from the client user; in the second instance, the request comes from the client machine. Therefore, an NIS+ principal can be a client user or a client machine.
(An NIS+ principal can also be the entity that supplies an NIS+ service from an NIS+ server. Since all NIS+ servers are also NIS+ clients, much of this discussion also applies to servers.)
Client
An NIS+ client is a machine that has been set up to receive NIS+ service. Setting up an NIS+ client consists of establishing security credentials, making it a member of the proper NIS+ groups, verifying its home domain, verifying its switch configuration file and, finally, running the NIS+ initialization script. (Complete instructions are provided in Part 2.)
An NIS+ client can access any part of the namespace, subject to security constraints. In other words, if it has been authenticated and has been granted the proper permissions, it can access information or objects in any domain in the namespace.
Although a client can access the entire namespace, a client belongs to only one domain, which is referred to as its home domain. A client's home domain is usually specified during installation, but it can be changed or specified later. All the information about a client, such as its IP address and its credentials, is stored in the NIS+ tables of its home domain.
There is a subtle difference between being an NIS+ client and being listed in an NIS+ table. Entering information about a machine into an NIS+ table does not automatically make that machine an NIS+ client. It simply makes information about that machine available to all NIS+ clients. That machine cannot request NIS+ service unless it is actually set up as an NIS+ client.
Conversely, making a machine an NIS+ client does not enter information about that machine into an NIS+ table. It simply allows that machine to receive NIS+ service. If information about that machine is not explicitly entered into the NIS+ tables by an administrator, other NIS+ clients will not be able to get it.
When a client requests access to the namespace, it is actually requesting access to a particular domain in the namespace. Therefore, it sends its request to the server that supports the domain it is trying to access. Here is a simplified representation:
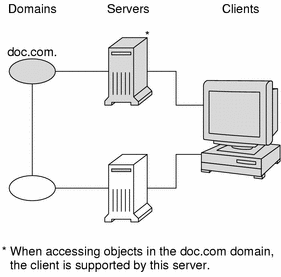
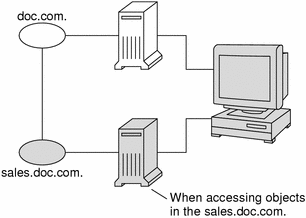
How does the client know which server that is? By trial and error. Beginning with its home server, the client tries first one server, then another, until it finds the right one. When a server cannot answer the client's request, it sends the client information to help locate the right server. Over time, the client builds up its own cache of information and becomes more efficient at locating the right server. The next section describes this process.
The Cold-Start File and Directory Cache
When a client is initialized, it is given a cold-start file. The cold-start file gives a client a copy of a directory object that it can use as a starting point for contacting servers in the namespace. The directory object contains the address, public keys, and other information about the master and replica servers that support the directory. Normally, the cold-start file contains the directory object of the client's home domain.
A cold-start file is used only to initialize a client's directory cache. The directory cache, managed by an NIS+ facility called the cache manager, stores the directory objects that enable a client to send its requests to the proper servers.
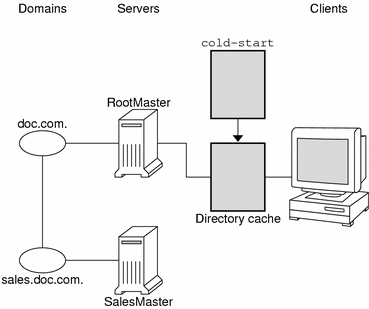
By storing a copy of the namespace's directory objects in its directory cache, a client can know which servers support which domains. (To view the contents of a client's cache, use the nisshowcache command, described in "The nisshowcache Command".) Here is a simplified example:
Domain Name and Directory Name are the same | Supporting Server | IP Address |
|---|---|---|
doc.com. | rootmaster | 123.45.6.77 |
sales.doc.com. | salesmaster | 123.45.6.66 |
manf.doc.com. | manfmaster | 123.45.6.37 |
int.sales.doc.com. | Intlsalesmaster | 111.22.3.7 |
To keep these copies up-to-date, each directory object has a time-to-live (TTL) field. Its default value is 12 hours. If a client looks in its directory cache for a directory object and finds that it has not been updated in the last 12 hours, the cache manager obtains a new copy of the object. You can change a directory object's time-to-live value with the nischttl command, as described in "The nischttl Command". However, keep in mind that the longer the time-to-live, the higher the likelihood that the copy of the object will be out of date; and the shorter the time to live, the greater the network traffic and server load.
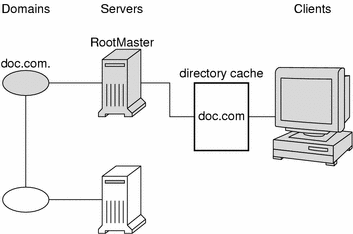
How does the directory cache accumulate these directory objects? As mentioned above, the cold-start file provides the first entry in the cache. Therefore, when the client sends its first request, the request goes to the server specified by the cold-start file. If the request is for access to the domain supported by that server, the server answers the request.
If the request is for access to another domain (for example, sales.doc.com.), the server tries to help the client locate the proper server. If the server has an entry for that domain in its own directory cache, it sends a copy of the domain's directory object to the client. The client loads that information into its directory cache for future reference and sends its request to that server.
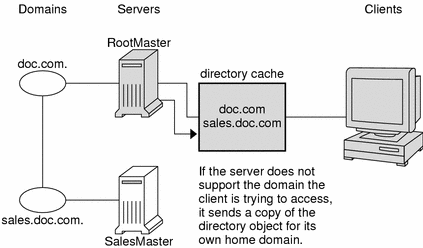
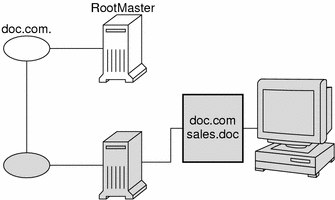
In the unlikely event that the server does not have a copy of the directory object the client is trying to access, it sends the client a copy of the directory object for its own home domain, which lists the address of the server's parent. The client repeats the process with the parent server, and keeps trying until it finds the proper server or until it has tried all the servers in the namespace. What the client does after trying all the servers in the domain is determined by the instructions in its name service switch configuration file.
Over time, the client accumulates in its cache a copy of all the directory objects in the namespace and thus the IP addresses of the servers that support them. When it needs to send a request for access to another domain, it can usually find the name of its server in its directory cache and send the request directly to that server.
An NIS+ Server Is Also a Client
An NIS+ server is also an NIS+ client. In fact, before you can set up a machine as a server, you must initialize it as a client. The only exception is the root master server, which has its own unique setup process.
This means that in addition to supporting a domain, a server also belongs to a domain. In other words, by virtue of being a client, a server has a home domain. Its host information is stored in the Hosts table of its home domain, and its DES credentials are stored in the cred table of its home domain. Like other clients, it sends its requests for service to the servers listed in its directory cache.
An important point to remember is that--except for the root domain--a server's home domain is the parent of the domain the server supports:
In other words, a server supports clients in one domain, but is a client of another domain. A server cannot be a client of a domain that it supports, with the exception of the root domain. Because they have no parent domain, the servers that support the root domain belong to the root domain itself.
For example, consider the following namespace:
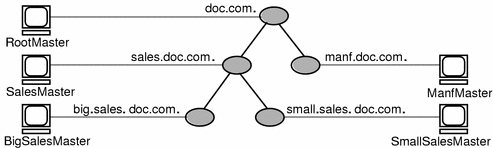
The chart lists which domain each server supports and which domain it belongs to:
Server | Supports | Belongs to |
|---|---|---|
RootMaster | doc.com. | doc.com. |
SalesMaster | sales.doc.com. | doc.com. |
IntlSalesMaster | intl.sales.doc.com. | sales.doc.com. |
ManfMaster | manf.doc.com. | doc.com. |
Naming Conventions
Objects in an NIS+ namespace can be identified with two types of names: partially-qualified and fully qualified. A partially qualified name, also called a simple name, is simply the name of the object or any portion of the fully qualified name. If during any administration operation you type the partially qualified name of an object or principal, NIS+ will attempt to expand the name into its fully qualified version. For details, see "Naming Conventions".
A fully qualified name is the complete name of the object, including all the information necessary to locate it in the namespace, such as its parent directory, if it has one, and its complete domain name, including a trailing dot.
This varies among different types of objects, so the conventions for each type, as well as for NIS+ principals, is described separately. This namespace will be used as an example:
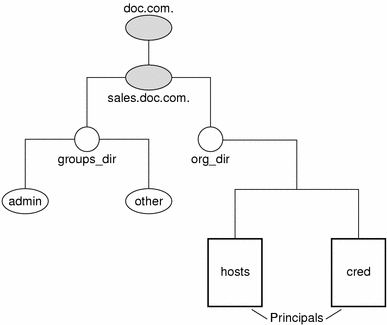
The fully qualified names for all the objects in this namespace, including NIS+ principals, are summarized below.
Figure 2-4 Fully qualified Names of Namespace Components
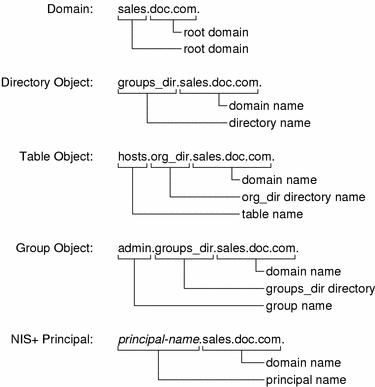
NIS+ Domain Names
A fully qualified NIS+ domain name is formed from left to right, starting with the local domain and ending with the root domain:
doc.com. (root domain)
sales.doc.com. (subdomain)
intl.sales.doc.com. (a third level subdomain)
The first line above shows the name of the root domain. The root domain must always have at least two elements (labels) and must end in a dot. The last (right most) label may be anything you want, but in order to maintain Internet compatibility, the last element must be either an Internet organizational name (as shown below), or a two or three character geographic identifier such as .jp. for Japan.
Table 2-4 Internet Organizational Domains
Domain | Purpose |
|---|---|
com | Commercial organizations |
edu | Educational institutions |
gov | Government institutions |
mil | Military groups |
net | Major network support centers |
org | Nonprofit organizations and others |
int | International organizations |
The second and third lines above show the names of lower-level domains.